
Kubernetes基本概念和术语
Kubernetes 基本概念和术语
Kubernetes中的大部分概念如Node、Pod、Replication Controller、Service等都可以看作一种“资源对象”,几乎所有的资源对象都可以通过Kubernetes提供的 kubectl 工具(或者API编程调用)执行增、删、改、查等操作并将其保存在etcd中持久化存储。从这个角度来看,Kubernetes其实是一个高度自动化的资源控制系统,它通过跟踪对比 etcd 库里保存的“资源期望状态”与当前环境中的“实际资源状态”的差异来实现自动控制和自动纠错的高级功能。
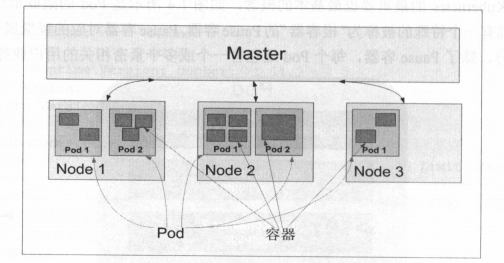
先了解一下 Kubernetes集群的两种管理角色:Master和 Node。
1. Master
Kubernetes里的 Master 指的是集群控制节点,每个Kubernetes集群里需要有一个Master节点来负责整个集群的管理和控制,基本上Kubernetes的所有控制命令都发给它,它来负责具体的执行过程,我们后面执行的所有命令基本都是在 Master 节点上运行的。Master节点通常会占据一个独立的服务器(高可用部署建议用3台服务器),如果宕机或者不可用,那么对集群内容器应用的管理都将失效。
Master节点上运行着以下一组关键进程。
Kubernetes API Server (kube-apiserver):提供了HTTP Rest接口的关键服务进程,是
Kubernetes里所有资源的增、删、改、查等操作的唯一入口,也是集群控制的入口进程。Kubernetes Controller Manager (kube-controller-manager): Kubernetes里所有资源对象的自动化控制中心。Kubernetes Scheduler (kube-scheduler):负责资源调度(Pod调度)的进程。
另外,在Master节点上还需要启动一个etcd 服务,因为Kubernetes里的所有资源对象的数据全部是保存在etcd 中的。
2.Node
与 Master一样,Node节点可以是一台物理主机,也可以是一台虚拟机。Node节点才是Kubernetes集群中的工作负载节点,每个Node都会被 Master分配一些工作负载(Docker容器),当某个Node’宕机时,其上的工作负载会被Master自动转移到其他节点上去。
每个Node节点上都运行着以下一组关键进程。
kubelet:负责Pod对应的容器的创建、启停等任务,同时与Master节点密切协作,实
现集群管理的基本功能。kube-proxy:实现Kubernetes Service的通信与负载均衡机制的重要组件。Docker Engine (docker):Docker引擎,负责本机的容器创建和管理工作。
Node节点可以在运行期间动态增加到Kubernetes集群中,前提是这个节点上已经正确安装、配置和启动了上述关键进程,在默认情况下kubelet 会向Master注册自己,这也是 Kubernetes推荐的Node管理方式。一旦Node被纳入集群管理范围,kubelet 进程就会定时向Master节点汇报自身的情报,例如操作系统、Docker版本、机器的CPU和内存情况,以及当前有哪些Pod在运行等,这样 Master可以获知每个Node的资源使用情况,并实现高效均衡的资源调度策略。而某个Node超过指定时间不上报信息时,会被Master 判定为“失联”,Node的状态被标记为不可用(Not Ready),随后Master 会触发“工作负载大转移”的自动流程。
1 | #查看集群有多少node |
通过kubectl describe node可以看到:
- Node基本信息:名称、标签、创建时间等。
- Node当前的运行状态,Node启动以后会做一系列的自检工作,比如磁盘是否满了,如果满了就标注
OutOfDisk=True,否则继续检查内存是否不足(如果内存不足,就标注MemoryPressure=True),最后一切正常,就设置为Ready状态(Ready=True),该状态表示Node处于健康状态,Master 将可以在其上调度新的任务了(如启动Pod)。 - Node的主机地址与主机名。
- Node 上的资源总量:描述Node可用的系统资源,包括 CPU、内存数量、最大可调度Pod数量等,注意到目前Kubernetes已经实验性地支持GPU资源分配了(
alpha.kubernetes.io/nvidia-gpu=0)。 - Node可分配资源量:描述Node当前可用于分配的资源量。
- 主机系统信息:包括主机的唯一标识UUID、Linux kernel版本号、操作系统类型与版本、Kubernetes版本号、kubelet 与 kube-proxy的版本号等。
- 当前正在运行的Pod列表概要信息。
- 已分配的资源使用概要信息,例如资源申请的最低、最大允许使用量占系统总量的百分比。
- Node相关的 Event信息。
3.Pod
每个Pod都有一个特殊的“根容器”Pause容器。这个容器是Kubernetes的一部分。并且Pod中包含一个或多个紧密相关的用户业务容器。

为什么需要Pod
- 在一组容器作为一个单元的情况下,我们难以对“整体”简单地进行判断及有效地进行行动。引入业务无关并且不易死亡的Pause容器作为Pod 的根容器,以它的状态代表整个容器组的状态,就简单、巧妙地解决了这个难题。
- Pod里的多个业务容器共享Pause容器的IP,共享Pause容器挂接的Volume,这样既简化了密切关联的业务容器之间的通信问题,也很好地解决了它们之间的文件共享问题。
Pod的类型
Pod 其实有两种类型:普通的 Pod 及静态 Pod (Static Pod ),后者比较特殊,它并不存放在Kubernetes的etcd 存储里,而是存放在某个具体 Node 上的一个具体文件中,并且只在此 Node上启动运行。 而普通的 Pod 一旦被创建,就会被放入到 etcd 中存储,随后会被 Kubernetes Master 调度到某个具体的 Node 上并进行绑定( Binding ),随后该 Pod 被对应的 Node 上的 kubelet 进程实例化成一组相关 Docker 容器并启动起来。在默认情况下,当 Pod 里的某个容器停止时Kubernetes 会自动检测到这个问题并且重新启动这 Pod (重启 Pod 里的所有容器),如 Pod所在的 Node 岩机,则会将这个 Node 上的所有 Pod 重新调度到其他节点上。
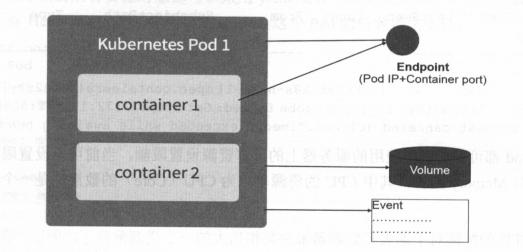
Pod的yaml文件和基本情况
Kubernetes 的所有资源对象都可以采用 yaml 或者 JSON 格式的文件来定义或描述
1 | apiVersion : vl |
Kind为 Pod 表明这是一个 Pod 的定义, metadata 里的 name 属性为 Pod 的名字, metadata里还能定义资源对象的标签( Label ),这里声明 myweb 拥有一个 name=myweb 的标签( Label )。Pod 里所包含的容器组的定义则在 spec 一节中声明,这里定义了一个名字为 myweb的容器,并注入了MYSQL_SERVICE_HOST和MYSQL_SERVICE_PORT 两个环境变量。并且在 8080 端口 container Port)上启动容器进程。
Pod 加上容器端口 containerPort ,就组成了 个新的概念一Endpoint,它代表着此 Pod 里的 个服务进程的对外通信地址。一个 Pod 也存在着具有多个Endpoint 的情况,比如当我们把 Tomcat 定义为一个 Pod 时,可以对外暴露管理端口与服务端口这两个 Endpoint。
Docker Volume 在Kubernetes 里也有对应的概念 Pod Voiume ,后者有些扩展,比如可以用分布式文件系统 GlusterFS 实现后端存储功能: Pod Volume 是定义在 Pod之上,然后被各个容器挂载到自己的文件系统中的。
Kubernetes Event
Event 是一个事件的记录,记录了事件的最早产生时间、最后重现时间、重复次数、发起者、类型,以及导致此事件的原因等众多信息。 Event通常会关联到某个具体的资源对象上,之前我们看到 Node 的描述信息包括了 Event,而 Pod 同样有 Event 记录,当我们发现某个 Pod 迟迟无法创建时,可以用kubectl describe pod xxx查看描述信息,用来定位问题的原因。
Pod资源
每个 Pod 都可以对其能使用的服务器上的计算资源设置限额,当前可以设置限额的计算资源有 CPU、 Memory 两种,其中 CPU 的资源单位为 CPU (Core)的数量,是一个绝对值而非相对值。
一个CPU对绝大多数容器来说是很大的资源配额,所以k8s中通常用千分之一的CPU配额为最小单位,用m表示。通常一个容器的 CPU 配额被定义100300m ,即占用 0.10.3 CPU 。由于 CPU 配额是一个绝对值,所以无论在拥有一个Core 的机器上,还是在拥有 48 Core 的机器上,100m 这个配额所代表的 CPU 的使用量都是一样的。Memory 配额也是一个绝对值,它的单位是内存字节数
k8s中,进行限额需要设定一下两个参数:
Requests:该资源的最小申请量。Limits:该资源最大允许使用的量,不能被突破,当容器试图使用超过这个量的资源时,可能会被Kubernetes Kill并重启。
通常会把 Request 设置为 个比较小的数值,符合容器平时的工作负载情况下的资源需求,而把 Limit 设置为峰值负载情况下资源占用的最大量。
1 | #比如下面这段定义,表明 MySQL容器申请最少 0.25个CPU 64MiB 内存,在运行过程中 MySQL 容器所能使用的资源配额为0.5个CPU和128MiB 内存: |
4.Label
Label是key=value的键值对,其中 key、value 由用户自己指定。 Label 可以附加到各种资源对象上,例如 Node、Pod、Service、RC 等,一个资源对象可 以定义任意数量的 Label ,同一个 Label 也可以被添加到任意数量的资源对象上去 ,Label 通常在资源对象定义时确定,也可以在对象创建后动态添加或者删除。
过给指定的资源对象捆绑一个或多个不同的 Label 来实现多维度的资源分组管理功能,以便于进行资源分配、调度、配置、部署等管理工作。例如:部署不同版本的应用到不同的环境中:或者监控和分析应用(日志记录、监控、告警)等
版本标签:”release”:”stable “,”release “:”can “
环境标签:”environment”:”dev”,”environment”:”qa”,”environment”:”production”
架构标签:”tier”:”frontend”, “tier”:”backend”, “tier”:”middleware”
分区标签:”partition”:”customerA”,”partition”:”customerB”
质量管控标签:”track “:”daily”, “track”:”weekly”
Label Selector 可以被类比为 SQL 语句中的 where 查询条件,例如, name=redis-slave 这个Label Selector 作用于 Pod 时,类比为 select *from pod where pod’s name ='redis-slave'这样的语句。
有两种 Label Selector 的表达式:基于等式的( Equality-based )和基于集合的(Set-based ),前者采用“等式类”的表达式匹配标签
name = redis-slave:匹配所有具有标签name=redis-slave的资源对象env != production:匹配所有不具有标签env=production的资源对象
而后者则使用集合操作的表达式匹配标签
name in (redis-master,redis-slave):匹配所有具有标签name=redis-master或者name=redis-slave的资源对象- `name not in ( php-frontend
- :匹配所有不具有标签 name=php-frontend 的资源对象。
新出现的管理对象如 Deplopment 、ReplicaSet 、Daemon Set、 Job 可以在 Selector 中使用基于集合的筛选条件定义
1 | selector: |
matchLabels 于定义一组 Label 与直接写在 Selector 作用相同 matchExpressions,用于定义一组基于集合的筛选条件,可用 的条件运算符包括 In、Notin、Exists、DoesNotExist。果同时设置了 matchLabel matchExpressions ,则两组条件为“AND ”关系
Label Selector应用场景
kube-controller进程通过资源对象 RC 上定义的Label Selector来筛选要监控的 Pod 副本的数 ,实现Pod 副本的数量始终符合预期设定。
kube-proxy进程通过Service的Label Selector来选择对应的 Pod ,自动建立起每个Service 到对应 Pod 的请求转发路由表,从而实现 Service 的智能负载均衡机制
对某些 Node 定义特定的 Label ,并且在 Pod 定义文件中使用
NodeSelector这种标签调度策略, kube heduler 进程可以实现 Pod “定向调度”的特性。
5.Replication Controller
定义了 个期望的场景,即声明某种 Pod 的副本数量在任意时刻都符合某个预期值,包括如下几个部分。
- Pod 待的副本数( replicas )。
- 用于筛选目标 Pod Label Selector.
- Pod 的副本数量小于预期数量时,用 建新 Pod Pod 模板( template)
1 | apiVersion: vl |
Controller Manager接收RC的定义消息,定期检查当前目标存活的Pod,保证Pod数量等于RC的期望值,如果Pod数量多于期望值,就会停掉一下Pod。
动态缩放Pod:通过 kubectl scale
1 | kubectl scale re redis-slave --replicas=3 |
删除 RC 并不会影响通过该 RC 己创建好的 Pod 。
RC提供了滚动升级
RC已经升级为Replica Set,下一代的RC,支持基于集合的 Label selector ( Set-based selector )。RC只支持等式。
1 | apiVersion: extensions/v1beta1 |
主要被 Deployment 资源对象所使用,形成一套Pod 创建、删除、更新的编排机制 。
Replica Set特性和作用:
- 实现 Pod 的创建过程及副本数量的自动控制。
- 完整的 Pod 定义模板。
- 通过 Label Selector 机制实现对 Pod 副本的自动控制。
- 改变 RC 里的 Pod 副本数 ,可以实现 Pod 的扩容或缩容功能。
- 改变 RC Pod 模板中的镜像版本,实现Pod 的滚动升级功能。
6.Deployment
解决 Pod 的编排问题。使用了 Replica Set 来实现目的。可以随时知道当前 Pod “部署”的进度。一个 Pod 的创建、调度、绑定节点及在目标 Node 上启动对应的容器这一完整过程需要一定的时间,所以我们期待系统启动 Pod 副本的目标状态,实际上是 个连续变化的“部署过程”导致的最终状态。
使用场景
- 生成对应的 Replica Set 并完成 Pod 副本的创建过程。
- 检查 Deployment 的状态来看部署动作是否完成。
- 更新 Deployment 以创建新的 Pod。
- 回滚到 个早先的 Deployment 版本。
- 暂停 Deployment 以便于一次性修改多个
PodTemplateSpec的配置项,之后再恢复Deployment ,进行新的发布。 - 扩展 Deployment 以应对高负载。
- 查看 Deployment 的状态,以此作为发布是否成功的指标。
- 清理不再需要的旧版本 ReplicaSets。
使用
与Replica Set相似
1 | apiVersion : extensions/v1beta1 |
创建:
1 | kubectl create -f tomcat-deployment.yaml |
查看
1 | kubectl get deployments |
参数解释:
| 参数 | 解释 |
|---|---|
| DESIRED | Pod副本数量的期望值,replica |
| CURRENT | 当前 replica的值Deployment Replica 里的 Replica值,这个值不断增加,直到达到 DESIRED 为止 表明整个部署过程完成。 |
| UP-TO-DATE | 最新版本 Pod 的副本数量,用于指示在滚动升级的过程中,有多少Pod 副本已经成功升级。 |
| AVAILABLE | 当前集群中可用的 Pod 副本数量 |
查看RS
1 | kubectl get rs |
查看Deployment控制的Pod水平扩展过程
1 | kubectl describe deployments |
7.Horizontal Pod Autoscaler
Pod 横向自动扩容,简称HPA。通过追踪分析 RC控制的所有目标 Pod 的负载变化情况,来确定是否需要针对性地调整目标 Pod 的副本数。Pod负载度量指标:
CPUUtilizationPercentage。- 应用程序自定义的度量指标,比如服务在每秒内的相应的请求数 (TPS或 QPS )。
CPUUtilizationPercentage算数平均值,目标Pod所有副本自身的CPU利用率平均值。一个 Pod 自身的 CPU 利用率是该 Pod 当前 CPU 的使用量除以它的 Pod Request 的值
8.StatefulSet
Pod 的管理对象 RC、Deployment、 DaemonSet 、Job 都是面向无态的服务。但MySQL集群、MongoDB 集群、 Akka 集群 ZooKeeper 集群等,这些集群都有一些特定:
- 每个节点都有固定身份ID,通过ID集群成员可以相互发现并通信。
- 集群规模固定,不能随意变动。
- 每个节点有状态,通常会持久化数据到永久存储中。
- 磁盘坏掉,某个节点无法正常运行,集群功能受损。
通过Deploment创建的Pod名字是随机的,IP也是运行期才能确定的,并且为了能够在其他节点上回复失败的节点,需要挂载共享存储。k8s引入了StatefulSet ,它有以下特性:
- 的每个 Pod 都有稳定、唯一的网络标识,设 StatefulSet 名字叫 kafka, ,那么第 Pod kafka-0 ,第 个叫 kafka-1 .
- Pod 副本的启停顺序是受控的。
- 的 Pod 采用稳定的持久化存储卷,通过 PV/PVC 来实现,删除 Pod 时默认不会删除与 Statefu!Set 相关的存储卷。
StatefulSet 除了要与 PV 卷捆绑,还要与 Headless Service 配合使用, Headless Service 与普Service 的关键区别在于,它没有 Cluster IP ,如果解析 Headless Service的 DNS 域名,则返回的是该 Service 对应的全部 Pod的Endpoint 列表 Stateful Set ,在Headless Service 的基础上又Stateful Set 控制的每个 Pod 实例创建了 DNS 域名
1 | $(podname).$(headless service name) |
9.Service
概述
每个Service 微服务架构中的一个“微服务”。Pod和RC都是为Serivce服务的。
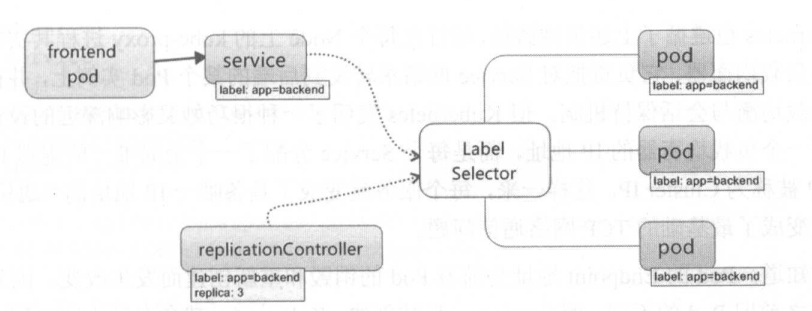
Service 定义了一个服务的访问入口地址,前端的应用Pod 通过这个入口地址访问其背后的一组由 Pod 副本组成的集群实例,Service 与其后端 Pod副本集群之间则是通过 Label Selector 来实现对接。而 RC 的作用实际上是保证 Service的服务能力和服务质量始终处于预期的标准。
我们的系统由多个提供不同业务能力而又彼此独立的微服务单元所组成,服务之间通过 TCP/IP 进行通信,从而形成了我们强大而又灵活的弹性网格,拥有了强大的分布式能力、弹性扩展能力、容错能力。
每个 Pod 都提供了一个独立的 Endpoint,通常部署一个负载均衡器(软件或硬件),为这组 Pod 开启一个对外的服务端口如8000 端口, 并且将这些 Pod Endpoint 列表加入 8000 端口的转发列中,客户端就可以通过负载均衡器的对外IP地址+服务端口来访问此服务。
运行在每个 Node 上的 kube-proxy 其实就是 个智能的软件负载均衡器,负责把对 Service 的请求转发到后端的某个 Pod 实例上,井在内部实现服务的负载均衡与会话保持机制。
Service不是共用一个负载均衡器的IP地址,而是每个 Service 分配了 全局唯一的虚拟 IP 地址,这个虚拟 被称为 Cluster IP 。这样一来,每个服务就 成了具备唯一IP地址的“通信节点”。
Service 的整个生命周期内,它的 Cluster IP不会发生改变,服务发现,用 Service Name和 Service的Cluster IP 地址做 DNS 域名映射就可以解决。
1 | #的服务端口为8080,拥有"tier=frontend ”这个 Label的所有Pod实例都属于它 |
1 | #创建 |
Service 多端口问题:
很多服务都存在多个端口的问题,通常一个端口提供业务服务,另外一个端口提供管理服务,比如 Mycat Codis 等常见中间件,Kubernetes Service 支持多个 Endpoint ,在存在多个 Endpoint的情况下,要求每个 Endpoint 定义一个名字来区分:
1 | apiVersion : vl |
为什么给端口命名? k8s的服务发现机制。
kubernetes服务发现机制
大部分分布式系统通过提供特定的API 接口来实现服务发现的功能,但这样做会导致平台的侵入性比较强。
Kubernetes 中的 Service 都有一个唯一的 Cluster 及唯一的名字,而名字是由开发者自己定义的,部署时也没必要改变。最早时 Kubernetes 采用了 Linux 环境变量的方式解决这个问题,即每个 Service 生成 些对应的 Linux 环境变量 ENV ,并在每个 Pod 的容器在启动时,自动注入这些环境变量。后来Kubernetes 通过 Add-On 增值包的方式引入了 DNS 系统,把服务名作为 DNS 域名,这样程序就可以直接使用服务名来建立通信连接了。
外部系统访问Service
k8s的三种IP:
Node IP
Node 节点的 IP 地址。物理网卡的 IP 地址,这是个真实存在的物理网络,所有属于这个网络的服务器之间都能通过这个网络直接通信。
Pod IP
Pod IP 地址。Docker Engine 根据 docker0网桥的 地址段进行分配的,通常是一个虚拟的二层网络。不同Node上的Pod需要彼此通信,是通过 Pod 在的虚拟二层网络进行通信的,而真实的 TCP/IP 则是通过 Node 在的物理网卡流出的
Cluster IP
Service 的IP地址。虚拟的 IP:
- 仅作用 Kubenetes Service 这个对象,并由 Kubenetes 管理和分配 IP.
- Cluster 无法被 Ping,没有一个“实体网络对象”来响应
- Cluster 只能结合 Service Port 组成 个具体的通信端口,,单独的 Cluster 具备TCP/IP 基础 并且它们属于 Kubernetes 集群这样 个封闭的空间, 集群之外的节点如果要访问这个通信端口 ,则需要 一些额外的工作
- kubernetes 集群之内,
Node IP网、Pod IP网与Cluster IP网之间的通信采用的是Kubernetes 自己设计的一种编程方式的特殊的路由规则。
service如何被集群外部访问?1
1.采用 NodePort
1 | apiVersion : vl |
NodePort 实现方式是在 Kubernetes 集群里的每个 Node 上为需要外部访问的 Service 开启个对应的 TCP 监听端口,外部系统只要用任意 Node IP 地址+具体的 odePort 端口号
1 | #查看端口监听 |
NodePort无法解决负载均衡问题
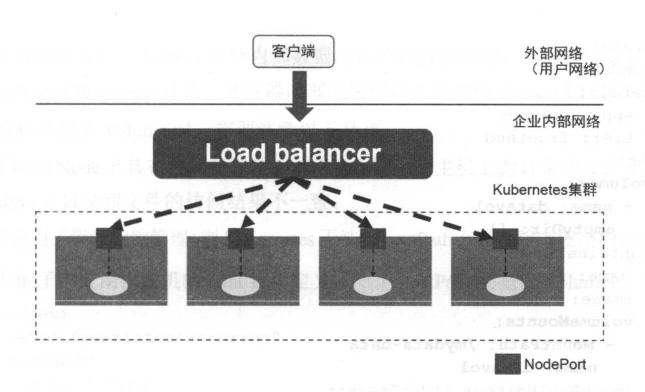
Load balancer 组件独立于 Kubernetes 集群之外,例如 HAProxy 或者 Nginx 。
10 Volume (存储卷)
Kubernetes Volume 概念、用途和目的与 Docker Volume 比较类似,但不同
- Kubernetes 中的Volume 定义在 Pod上,然后被 Pod 里的多个容器挂载到具体的文件目录下;
- Kubernetes 中的 Volume与Pod 的生命周期相同,但与容器的生命周期不相关,当容器终止或者重启时, Volume 中的数据也不会丢失。
- Kubernetes 支持多种类型的 Volume ,例如
GlusterFS、Ceph等先进的分布式文件系统
使用方式:先在 Pod 上声明 Volume ,然后在容器里引用该 Volume Mount 到容器里的某个目录上
1 | template: |
可以让 Pod里的多个容器共享文件、让容器的数据写到宿主机的磁盘上或者写文件到网络存储中, kubernetes Volume 还扩展出了一种非常有实用价值的功能,即容器配置文件集中化定义与管理,这是通过 ConfigMap 个新的资源对象来实现的。
Kubernetes 提供了非常丰富的 Volume 类型
1.emptyDir
在 Pod 分配到 Node 时创建的,初始内容为空,并且无须指定宿主机上对应的目录文件,Pod Node 上移除时, empty 中的数据也会被永久删除。 作用:
- 临时空间,例如用于某些应用程序运行时所需的临时目录
- 长时间任务的中间过程
CheckPoint的临时保存目录 - 一个容器需要从另一个容器中获取数据的目录
如果 kubelet 的配置是使用硬盘,那么所emptyDir让都将创建在该硬盘上。
2.hostPath
为在 Pod 上挂载宿主机上的文件或目录
- 容器应用程序生成的日志文件需要永久保存时,可以使用宿主机的 速文件系统进行存储。
- 需要访问宿主机上 Docker引擎内部数据结构的容器应用时,可以通过定义 hostPath宿主机
/var/lib/docker目录,使容器内部应用可以直接访问 Docker 的文件系统
有几点需要注意
- 不同的 Node 上具有相同配置的 Pod 可能会因为宿主机上的目录和文件不同而导致对Volume 上目录和文件的访问结果不一致。
- 如果使用了资源配额管理,则 Kubernetes 无法将 hostPath 在宿主机上使用的资源纳入管理。
1 | volumes: |
3.NFS
使用 NFS文件系统提供的共享目录存储数据时,我们需要在系统中部署 NFS Server 定义 NFS 类型的 Volume 示例如下
1 | volumes : |
11.Persistent Volume
Volume 是定义在 Pod 的,属于“计算资源”的一部分,“网络存储”是相对独立于“计算资源”而存在的一种实体资源。在使用虚拟机的情况下,我们通常会先定义 个网络存储,然后从中划出一个“网盘”并挂接到虚拟机上。 Persistent Volume(简称 PV )和与之相关联的 Persistent Volume Claim (简称 PVC )也起到了类似的作用。
PV 可以理解成 Kubemetes 集群中 的某个网络存储中对应的一块存储
- PV 只能是网络存储,不属于任何 Node ,但可以在每个 Node 上访问。
- PV 不是定义在 Pod 上的 ,而是独立于 Pod 之外定义。
NFS 类型 PV 的一个 yam! 定义文件
1 | apiVersion: vl |
accessModes 属性
ReadWriteOnce读写权限、并且只 能被单个 Node 挂载ReadOnlyMany只读权限、允许被多 Node 挂载ReadWriteMany读写权限、允许被多个 Node 挂载
Pod 想申请某种类型的 PV,则首先需要定义一个 PersistentVolurneClaim (PVC )
1 | kind: PersistentVolumeClaim |
然后,在 Pod Volume 定义中引用上述 PVC 即可:
1 | volumes: |
PV 是有状态的对象,它有以下几种状态
- Available :空闲状态。
- Bound :己经绑定到某个 PVC 上。
- Released :对应的 PVC 己经删除,但资源还没有被集群收回
- Failed: PV 自动回收失败。
12.Namespace(命名空间)
Namespace 在很多情况下用于实现多租户的资源隔离。 Namespace 通过将集群内部的资源对象“分配”到不同的Namespace 中,形成逻辑上分组的不同项目、小组或用户组,便于不同的分组在共享使用整个集群的资源的同时还能被分别管理。
Kubemetes 集群在启动后,会创建一个名为“default ”的 Namespace
1 | kubectl get namespaces |
如果不特别指明 Namespace ,则用户创建的 Pod RC Service 都将被系统创建到这个默认的名为 default Namespace 中。
1 | apiVersion: vl |
创建了 Namespace ,我们在创建资源对象时就可以指定这个资源对象属于哪个Namespace
1 | apiVersion: vl |
kubectl get只能查看default命名空间的资源对象。
1 | kubectl get pods --namespace=development |
当我们给每个租户创建一个 Namespace 来实现多租户的资源隔离时,还能结合kubernetes的资源配额管理,限定不同租户能占用的资源,例如 CPU 使用量、内存使用量等.




