
深入Pod
一、Pod 定义详解
pod的定义文件完整内容:
1 | apiVersion : vl |
二、Pod 的基本用法
Pod的运行方式
在使用 Docker 时,可以使用docker run 命令创建井启动一个容器。而在 Kubernetes 系统中对长时间运行容器的要求是:其主程序需要一直在前台执行。
如果我们创建的 Docker 镜像的启动命令是后台执行程序,例如 Linux 脚本:
1 | nohup . /start.sh & |
则在 kubelet 创建包含这个容器的 Pod 之后运行完该命令, 即认为 Pod运行结束,将立刻销毁该Pod 。如果为该 Pod 定义了 ReplicationController ,则会监控到该 Pod 已经终止,根据RC定义的Pod的replicas副本数量生成一个新的Pod。这样会一直陷入循环。
对于前台执行的应用,可以使用开源工具 Supervisor 辅助进行前台运行的功能。 Supervisor 提供了一种可以同时启动多个后台应用,并保持 Supervisor 自身在前台执行的机制。
Pod 对容器的封装和应用
Pod 可以由一个或多个容器组合而成。
名为台ontend Pod 只由一个容器组成:
1 | apiVersion: vl |
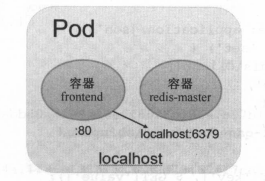
当 frontend和redis 两个容器应用为紧辑合的关系,应该组合成一个整体对外提供服务时,应将这两个容器打包为一个 Pod ,
1 | apiVersion : v l |
属于一个 Pod 容器应用之间访问时仅需要通过 localhost 就可以通信 ,使得这一组容器被绑定”在了一个环境。
三、静态Pod
静态 Pod 是由kubelet进行管理的仅存在于特定 Node上的Pod 。不能通过 API Server 进行管理 ,无法与 ReplicationController、 Deployment 或者 DaemonSet 进行关联。井且 kubelet也无法对它 进行健康检查。
创建静态 Pod 有两种方式:配置文件方式和 HTTP方式
配置文件
设置 kubelet 的启动参数 --config ,指定 kubelet 需要监控的配置文件所在的目录, kubelet 会定期扫描该目录 。并根据该目录中 yaml或json 进行 建操作。
假如配置目录为/etc/kubelet.d/ 配置启动参数:--config=/etc/kubelet.d/ 然后重启 kubelet 服务。然后在目录中放入需要启动的静态Pod的yaml文件,就会启动。
这个静态pod可以通过kubectl get获得查看,但是无法通Api Server直接管理,所以无法在Master节点删除,只会让Pod编程Pending状态。删除该Pod只能在节点配置目录下将yaml文件删除。
HTTP
设置 kubelet 的启动参数--manifest-url , kubelet 将会定期从该 URL 地址下载 Pod定义文件,并以yaml /json 文件的格式进行解析,然后创建 Pod 。
四、Pod容器共享Volume
在同一个 Pod 中的多个容器能够共享 Po 级别的存储卷 Volume V
1 | #Pod包含两个容器:tomcat busybox ,在 Pod级别设置 Volume "app-logs"用于 tomcat 向其中写日志文件, busybox读日志文件。 |
设置 Volume app-logs 类型 emptyDir, 挂载到 tomcat 器内的 /usr/local/tomcat/logs,同时挂载到 logreader容器 内的 logs 目录。tomcat 容器在启动后会/usr/local/tomcat/logs 目录 写文件, logreader器就可读取其中的文件了。
通过 kubectl logs 命令查看logreader 容器输出
1 | kubectl logs volume-pod -c busybox |
五、Pod 的配置管理
将应用所需的配置信息与程序进行分离,使得应用程序被更好地复用,通过不同的配置也能实现更灵活的功能。可以通过环境变量或者外挂文件的方式在创建容器时进行配置注入。
ConfigMap就提供了统一的配置管理。
1.ConfigMap概述
- 生成为容器内的环境变量。
- 设置容器启动命令的启动参数(需设置为环境变量)。
- 以 Volume 的形式挂载为容器内部的文件或目录。
ConfigMap 以一个或多个key:value的形式保存在 Kubernetes 系统中供应用使用,既可以用于表示一个变量的值,也可以用于表示一个完整配置文件的内容(例如server.xml =<?xml… > )
以通过yaml 配置文件或者直接使用 kubectl create configmap 命令行的方式来创建 ConfigMap。
2.创建ConfigMap资源对象
通过yaml配置文件创建
将几个应用所需的变量定义为ConfigMap:
1 | #cm-appvars.yaml |
使用ConfigMap
1 | #创建 |
将配置文件定义为configMap
1 | #cm-appconfigfiles.yaml |
通过 kubectl 命令行方式创建
接通过 kubectl create configmap 也可以创建 ConfigMap ,可以使用参数--from-file或 --from-literal 指定内容,并且可以在一行命令中指定多个参数。
通过
--from-file,从文件中创建,可以指定 key 的名称,也可以 个命令行中创建包含多个 key的ConfigMap1
kubectl create configmap NAME --from-file=[key=]source --from-file=[key=]source
通过
--from-file从目录中创建,该目录下的每个配置文件名都被设置为 key.文件的内容被设置为 value
1
kubectl create configmap NAME --from-file=config-files-dir
--from-literal从文本中创建建,直接将指定的key#=value#创建为 ConfigMap的内容1
kubectl create configmap NAME --from-literal=keyl=valuel --from-literal=key2=value2
示例:
1 | #当前目录下有配置文件 server.xml ,创建一个包含该文件内容的 ConfigMap: |
容器应用对configmap 的使用:
- 通过环境变量获取 Config 中的内容。
- 通过 Volume 挂载的方式将ConfigMap 的内容挂载为容器内部的文件或目录。
3.Pod 申使用 ConfigMap
环境变方式使用 ConfigMap
1 | #cm-configMap |
Pod cm-test-pod的定义中,将 cm-appvars 中的内容以环境变量(APP LOG LEVEL 和APPDATADIR )设置为容器内部的环境变量,容器的启动命令将显示这两个环境变量的值(env I grep APP):
1 | apiVersion: v1 |
创建
1 | kubectl create -f cm-test-pod.yaml |
k8s1.6之后有一个新字段envFrom、实现在Pod环境将ConfigMap中定义的key=value自动生成为环境变量。
1 | apiVersion: v1 |
volumeMount使用ConfigMap
1 | #cm-configMap |
Pod cm-test-app 的定义中,将ConfigMap cm-appconfigfiles 中的内容以文件的形式mount 容器内部的/configfiles 录中去。
1 | #cm-test-pod-volume |
创建Pod
1 | kubectl create -f cm-test-pod-volume.yaml |
如果在使用时不值当items,则会为容器内的目录中为每一个item生成一个文件名为key的文件。
4.使用 ConfigMap 的限制条件
ConfigMap 必须在 Pod 之前创建
ConfigMap Namespace 限制,只有处于相同 Namespaces 中的 Pod 可以引用它
ConfigMap 中的配额管理还未能实现
kubelet 只支持可以被
API Server管理的 Pod 使用 ConfigMap,kubelet 在本 Node 上通过
--manifest-url或--config自动创建的静态Pod 将无法引用 ConfigMapPod ConfigMap 进行挂载( volumeMount )操作时,容器内部只能挂载为“目录”,无法挂载为“文件”。在挂载到容器内部后,目录中将包含 ConfigMap 定义的每个 item,如果该目录下原来还有其他文件,则容器内的该目录将会被挂载的 ConfigMap 覆盖。可以将 ConfigMap挂载到容器内部的临时目录,再通过启动脚本将配置文件复制或者链接到( link命令)应用所用的实际配置目录下。
六.容器内获取Pod信息
Pod 在成功创建出来之后,都会被系统分配唯一的名字、IP地址, 井且处于某个 Nam space 中,如何在 Pod 容器内获取 Pod 这些重要信息呢?Downward API通过2种方式将Pod信息注入容器内部。
- 环境变量:用于单个变量,可以将 Pod 信息和 ontainer 信息注入容器内部。
- Volume 挂载:将数组类信息生成为文件,挂载到容器内部。
环境变量-将Pod信息注入为环境变量
1 | #dapi-test-pod-pod-vars.yaml |
metadata.name: Pod 名称,当 Pod 通过 RC 生成时,其名称是 RC 随机产生的唯一名称status.podIP: Pod 的回地址,之所以叫作 status.podIP 而非 metadata.IP 是因为 PodIP 属于状态数据,而非元数据
metadata.namespace: Pod 所在的 Namespace
1 | kubectl create -f dapi-test-pod-pod-vars.yaml |
环境变量-将容器资源信息注入为环境变量
通过 Downward API将Container 资源请求和 制信息注入容器环境变量中,容器应用使用 printenv命令印到标准输出中
1 | #dapi-test-pod-container-vars.yaml |
valueFrom 这种特殊的 Downward API 语法,目前 resourceFieldRef 可以将容器的资源请求和资源限制等配置设置为容器内部的环境变量。
requests.cpu:容器的 CPU 请求值limits.cpu容器的 CPU 限制值。requests.memory:容器的内存请求值limits.memory:容器的内存限制值
1 | kubectl create -f dapi-test-pod-container-vars.yaml |
Volume挂载方式
通过 Downward API 将Pod的Label 、Annotation 表通过 Volume 挂载为容器内的个文件,
1 | #dapi-test-pod-volume.yaml |
通过 items 设置,将会 path 的名称生成文件。这里将在容器内生成 /etc/ labels 和/etc/annotations 两个文件。
1 | #创建 |
Downward API作用:
集群中,每个节点都需要将自身的标识( ID )及进程绑定的 IP 地址等信息事先写入配置文件中 ,进程启动时读取这些信息,然后发布到某个类似服务注册中心的地方,以实现集群节点的自动发现功能。先编写个预启动脚本或 Init Container ,通过环境变量或文件方式获取 Pod 自身的名称 IP 地址等信息,然后写入主程序的配置文件中 最后启动主程序。
七、Pod生命周期和重启策略
Pod状态表
| 状态 | 描述 |
|---|---|
| Pending | API Server 己经创建该 Pod ,Pod 内还有个或多个容器的镜像没有创建,包括正在下镜像的过程 |
| Running | Pod 所有容器均己创建,且至少有一个容器处于运行状态、正在启动状态或正在重启状态 |
| Succeeded | Pod 内所有容器均成功执行退出 且不会再重启 |
| Failed | Pod 所有容器均已退出,但至少有一个容器退出为失败状态 |
| Unknown | 由于某种原因无法获取该 Pod 的状态 可能由于网络通信不畅导致 |
Pod 重启策略( RestartPolicy )应用于 Pod 内的所有容器,井且仅在 Pod 所处的 Node,kubelet 进行判断和重启操作。当当某个容器异常退出或者健康检查失败时, kubelet将根据 RestartPolicy 设置来进行相应的操作
Always当容器失效时,由 kubelet 动重启该容器。默认策略OnFailure当容器终止运行且退出码不为0时,由 kubelet 自动重启该容器。Never不论容器运行状态如何, kubelet 都不会重启该容器。
kubelet 重启失效容器的时间间隔以 sync-frequency 乘以 2n 来计算;例如1,2,4,8 倍等,最长延时 5min ,并且在成功重启后的 10min 后重置该时间。
Pod 重启策略与控制方式息息相关,当前可用于管理 Pod 的控制器包括ReplicationController、 Job、DaemonSet 及直接通过 kubelet 管理(静态 Pod )。每种控制器对 Pod的重启策略要求如下。
RC、Daemon Set:必须设置为 Always ,需要保证该容器持续运行。Job: OnFailure或Never ,确保容器执行完成后不再重启。kubelet:Pod 失效时自动重启它,不论将 RestartPolicy 设置为什么值,也不会对 Pod进行健康检查。
八、Pod健康检查
通过两类探针检查:LivenessProbe 和ReadinessProbe
LivenessProbe探针:于判断容器是否存活(running 状态),如果LivenessProbe探针探测到容器不健康,则 kubelet 将杀掉该容器,并根据容器的重启策略做相应的处理。如果 个容器不包含LivenessProbe探针,那么 kubelet 认为该容器的 LivenessProbe针返回的值永远是“ Success”ReadinessProbe探针:于判断容器是否启动完成( ready 状态),可以接收请求。如果ReadinessProbe探针检测到失败,则 Pod 的状态将被修改。Endpoint Controller将从Service Endpoint 中删除包含该容器所在 Pod Endpoint
九、Pod 调度
Pod 在大部分场景下都只是容器的载体而己,通常需要通过Deployment、DaemonSet 、Job 等对象来完成一组 Pod 的调度与自动控制功能。
1.Deployment/RC 全自动调度
自动部署一个容器应用的多份副本,以及持续监控副本数量在集群内始终维持用户指定的副本量。
1 | #nginx-deployment.yaml |
使用:
1 | #创建 |
调度策略上来说 Nginx Pod 由系统全自动调度。它们各自最终运行在哪个节点上完全由 Master Scheduler 一系列算法算得 ,用户无法干预调度过程和结果。
2. NodeSelector定向调度
实际情况中,也可能需要将 Pod 度到指定的一些 Node 上,可以通过 Node 的标签(Label) Pod的nodeSelector 属性相匹配实现定向调度。
对节点打标签
1
2
3
4
5
6kubectl label nodes <node-name> <label-key>=<label-value>
kubectl label nodes master role=master
kubectl get node --show-labels=true
NAME STATUS ROLES AGE VERSION LABELS
master Ready control-plane,master 7d23h v1.20.9 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=master,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,role=master在 Pod 定义中
nodeSelector的设置1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22#redis-master-controller.yaml
apiVersion: apps/v1
kind: Deployment
metadata :
name: redis-master-deployment
spec:
replicas: 1
selector:
matchLabels:
app: redis-master-deployment
template:
metadata:
labels:
app: redis-master-deployment
spec :
nodeSelector: #这个Pod运行在role=master的节点上
role: master
containers :
- name: master
image: kubeguide/redis-master
ports :
- containerPort : 6379kubectl create -f命令 Pod1
2
3#查看pod所在节点
kubectl get pods -o wide
redis-master-deployment-5445bf9f7c-227tw 1/1 Running 0 118s 173.24.0.22 master <none> <none>如果给多个Node 定义了相同的标签(例如 key=master ),则
scheduler将会根据调度算法从这组 Node 中选出一个可用 Node 进行 Pod 调度。
通过给集群不同Node贴不同标签,就可以在部署应用时根据应用的需求设置NodeSelector进行指定Node范围的选取。
如果我指定了
Pod nodeSelector条件,且集群中不存在包含相应标签Node则即使集群中还有其他可供使用的 Node ,这个 Pod 也无法被成功调度
Node Selector 通过标签 方式 简单 实现了限制 Pod 所在节点的方法。亲和性调度机制极大地扩展了 Pod 调度能力,主要功能如下:
- 可以使用软限制 、优先采用等限制方式代替之前的硬限制,这样调度器在无法满足优先需求的情况下,会退而求其次,继续运行该 Pod
- 依据节点上正在运行 Pod 的标签来进行限制,而非节点本身的标签这样就可以定义一种规 来描述 Pod 之间的亲和或互斥关系
亲和性调度功能包括节点亲和性(NodeAffmity )和 Pod 亲和 (PodAffinity )两个维度的设置。节点亲和性与 NodeSelector 类似,增强了上述前两点的优势; Pod 的亲和与互斥限制则通过 Pod 标签而不是节点标签来实现
3.NodeAffinity: Node亲和性调度
Node 亲和性的调度策略
RequiredDuringSchedulinglgnoredDuringExecution:必须满足指定的规则才可以调度 Pod到Node 上(功能与 nodeSelector 很像,但是使用的是不同的语法),相当于硬限制。PreferredDuringSchedulinglgnoredDuringExecution:强调优先满足指定规则,调度器尝试调度 Pod到Node ,但并不强求,相当于软限制 。多个优先级规则还可以设置权重( weight )值,以定义执行的先后顺序。
IgnoredDuringExecution 意思是:如果 Pod 所在的节点在 Pod 运行期间标签发生了变更,不再符合该 Pod 节点亲和性需求,则系统将忽略 Node Label 的变化,该 Pod 能继续在该节点运行。
4.DaemonSet:在每个 Node 上调度一个 Pod
于管理在集群中每个 Node仅运行一份 Pod 的副本实例
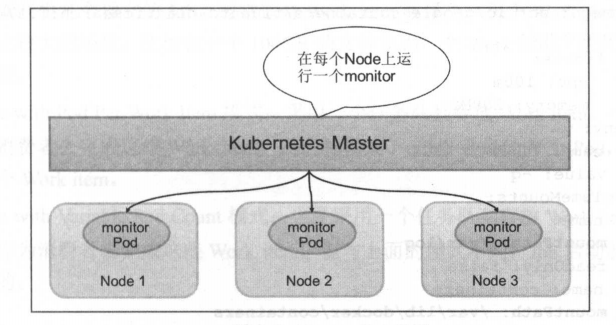
适合一些有这种需求的应用。
- 在每个 Node 上运行一个 GlusterFS 存储或者 Ceph 存储的 Daemon 进程。
- 在每个 Node 上运行一个日志采集程序,例如 Fluentd 或者 Logstach
- 在每个 Node 上运行一个性能监控程序,采集该 Node 的运行性能数据,例如 Prometheus、Node Exporter 、collectd 、New Relic agent 或者 Ganglia gmond 等。
1 | #fluentd-ds.yaml |
1 | #创建 |
5.Job:批处理调度
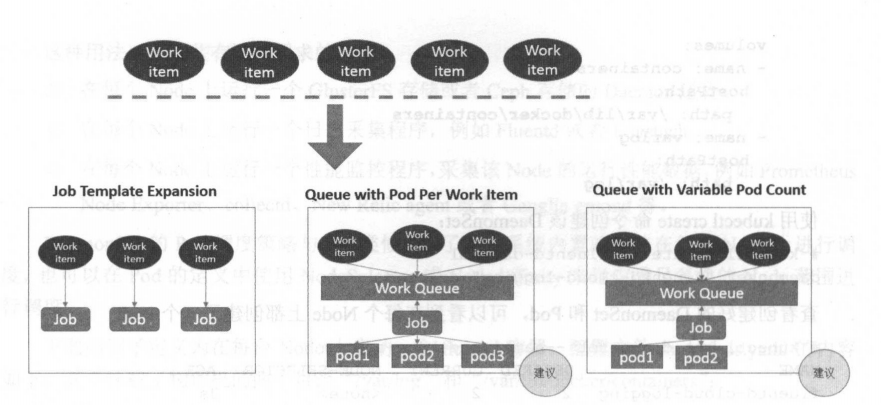
批处理任务通常并行( 串行)启动多批计算进程去处理一批工作项( work item ),处理完成后 整个批处任务结束。几种模式:
Job Template Expansion模式:一个 Job 应对应一个待处理的Work item,有 几个Work item就产生几个独立 Job ,通常适合 Work item 数量少 、每个 Work item 要处理的数据量比较大的场景, 如有一个 100GB的文件作为一个Work item, 总共 10 文件需要处理。Queue with Pod Per Work Item模式 :一个 队列任务存放Work item,一个 Job 对象作为消费者去完成这些 Work item, Job 会启动 Pod ,Job启动N个Pod,每个 Pod对应一个Work itemQueue with Variable Pod Count模式:也是采用一个任务队列存放Work item,一个 Job对象作为消费者去完成这些Work item但与上面模式不同, Job 启动 Pod 数量是可变的。
十、Init Container 初始化容器
在很多应用场景中、应用在启动之前都需要进行初始化操作
- 等待其他关联组件正确运行(例如数据库)
- 基于环境变量或配置模板生成配置文件。
- 从远程数据库获取本地所需配置,或者将自身注册到某个中央数据库中。
- 下载相关依赖包 或者对系统进行一些预配置操作。
于在启动应用容器( app container )之前启动一个或多个“初始 ”容器,完成应用容器所需的预置条件。Init container 与应用容器本质上是一样的 但它们是仅运行 次就结束的任务,并且必须在成功执行完成后,系统才能继续运行下一个容器。
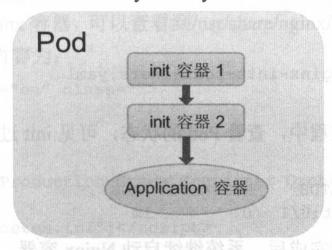
1 | #在启动 Nginx 之前,通过初始化容器 busybox Nginx 创建inde.html 主页文件。为 ini container Nginx 设置了一个共享的 volume ,以供 Nginx 访问init container 设置的 index.html 文件 |
init container与应用容器的区别:
运行方式不同,先于应用容器执行完成,当设置了多个init container时,将按顺序逐个运行,前一个initcontainer运行成功之后才能运行下一个。
init container的定义中也可以设置资源限制、 volume 的使用和安全策略- 果多个 init container 都定义了资源请求/资源限制,则取最大的值作为所有
init container的资源请求值/资源限制值 - Pod 的有效( effective )资源请求值/资源限制值取以下二者中的较大值
- 所有应用容器的资源请求值/资源限制值之和
- in it container 的有效资源请求值/资源限制值
- 调度算法将基于 Pod 的有效资源请求值/资源限制值进行计算,也就是说 init container 可以为初始化操作预留系统资源,即使后续应用容器无须使用这些资源。
- Pod 的有效 QoS 等级适用于 init container 和应用容器
- 资源配额和限制将根据 Pod 的有效资源请求值/资源限制值计算生效。
- Pod 级别的 cgroup 将基于 Pod 的有效资源请求/限制,与调度机制 致。
- 果多个 init container 都定义了资源请求/资源限制,则取最大的值作为所有
init container不能设置readinessProbe探针,因为必须在它们成功运行后才能继续运行Pod 中定义的普通容器Pod 重新启动( Restart )时 init container 将会重新运行,常见的 Pod 重启场最如下。
- init container 的镜像被更新时, init container 将会重新运行,导致 Pod 重启。仅更新应用容器的镜像只会使得应用容器被重启。
- Pod的infrastructure 容器(pause )更新时, Pod 将会重启。
- Pod 中的所有应用容器都终止了,并且 RestartPolicy=Always ,则 Pod 将会重启




