到目前为止,我们知道Spring创建Bean对象有5中方法,分别是:
- 使用
FactoryBean的getObject方法创建
- 使用
BeanPostProcessor的子接口InstantiationAwareBeanPostProcessor的postProcessBeforeInstantiation方法创建
- 设置
BeanDefinition的Supplier属性进行创建
- 设置
BeanDefinition的factory-method进行创建
- 使用全过程:
getBean-->doGetBean-->createBean-->doCreateBean 反射进行创建
现在讲述使用全过程创建一个Bean
解析构造函数
继续看AbstractAutowireCapableBeanFactory的createBeanInstance方法中的源码:
1
2
3
4
5
6
7
8
9
|
Constructor<?>[] ctors = determineConstructorsFromBeanPostProcessors(beanClass, beanName);
if (ctors != null || mbd.getResolvedAutowireMode() == AUTOWIRE_CONSTRUCTOR ||
mbd.hasConstructorArgumentValues() || !ObjectUtils.isEmpty(args)) {
return autowireConstructor(beanName, mbd, ctors, args);
}
...
|
在前面讲过InstantiationAwareBeanPostProcessor 是用来提前实例化对象的,而SmartInstantiationAwareBeanPostProcessor 是InstantiationAwareBeanPostProcessor 的子接口
determineConstructorsFromBeanPostProcessors方法就是解析构造函数的方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| protected Constructor<?>[] determineConstructorsFromBeanPostProcessors(@Nullable Class<?> beanClass, String beanName)
throws BeansException {
if (beanClass != null && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
Constructor<?>[] ctors = ibp.determineCandidateConstructors(beanClass, beanName);
if (ctors != null) {
return ctors;
}
}
}
}
return null;
}
|
可以看到这个方法是用来解析BeanClass的构造函数的,SmartInstantiationAwareBeanPostProcessor的实现类AutowiredAnnotationBeanPostProcessor,这个类是用来解析确定合适的构造函数,重点解析了@Autowired注解,并且还解析了@Value注解和@Lookup注解。
实例化
当解析出来构造函数之后,那么就调用autowireConstructor方法进行实例化,解析时会new一个构造器解析器ConstructorResolver ,在解析factoryMethod时也是使用的这个类使用的是instantiateUsingFactoryMethod这个方法,并且解析factoryMethod更加复杂,需要判断是否是静态的工厂创建还是实例工厂创建,而自动装配的构造解析相对来说简单一些,使用autowireConstructor方法进行解析。
构造函数注入
最终解析出构造方法和构造参数之后进行实例化,位于 ConstructorResolver#autowireConstructor
1
2
|
bw.setBeanInstance(instantiate(beanName, mbd, constructorToUse, argsToUse));
|
实例化:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| private Object instantiate(
String beanName, RootBeanDefinition mbd, Constructor<?> constructorToUse, Object[] argsToUse) {
try {
InstantiationStrategy strategy = this.beanFactory.getInstantiationStrategy();
if (System.getSecurityManager() != null) {
return AccessController.doPrivileged((PrivilegedAction<Object>) () ->
strategy.instantiate(mbd, beanName, this.beanFactory, constructorToUse, argsToUse),
this.beanFactory.getAccessControlContext());
}
else {
return strategy.instantiate(mbd, beanName, this.beanFactory, constructorToUse, argsToUse);
}
}
catch (Throwable ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Bean instantiation via constructor failed", ex);
}
}
|
根据实例化策略,来实例化对象,SimpleInstantiationStrategy#instantiate
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| @Override
public Object instantiate(RootBeanDefinition bd, @Nullable String beanName, BeanFactory owner,
final Constructor<?> ctor, Object... args) {
if (!bd.hasMethodOverrides()) {
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedAction<Object>) () -> {
ReflectionUtils.makeAccessible(ctor);
return null;
});
}
return BeanUtils.instantiateClass(ctor, args);
}
else {
return instantiateWithMethodInjection(bd, beanName, owner, ctor, args);
}
}
|
如果前面的解析都没有得到到Bean,那么就会使用无参构造函数进行解析:
1
2
3
4
5
6
7
8
9
10
|
ctors = mbd.getPreferredConstructors();
if (ctors != null) {
return autowireConstructor(beanName, mbd, ctors, null);
}
return instantiateBean(beanName, mbd);
|
无参构造器
一般都会从这里instantiateBean方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| protected BeanWrapper instantiateBean(String beanName, RootBeanDefinition mbd) {
try {
Object beanInstance;
if (System.getSecurityManager() != null) {
beanInstance = AccessController.doPrivileged(
(PrivilegedAction<Object>) () -> getInstantiationStrategy().instantiate(mbd, beanName, this),
getAccessControlContext());
}
else {
beanInstance = getInstantiationStrategy().instantiate(mbd, beanName, this);
}
BeanWrapper bw = new BeanWrapperImpl(beanInstance);
initBeanWrapper(bw);
return bw;
}
catch (Throwable ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Instantiation of bean failed", ex);
}
}
|
这里可以看到前面使用factoryMethod 和autowireConstructor 解析构造函数进行实例化还是使用无参构造函数进行实例化都是将Bean进行了包装,那这个包装有啥作用呢?
BeanWrapper的作用
BeanWrapper的使用地方
factory-method 解析:ConstructorResolver#instantiateUsingFactoryMethod 方法。SmartInstantiationAwareBeanPostProcessor子类AutowiredAnnotationBeanPostProcessor 解析出构造函数,然后使用ConstructorResolver#autowireConstructor 执行。
这2除都存在:
1
2
3
4
|
BeanWrapperImpl bw = new BeanWrapperImpl();
this.beanFactory.initBeanWrapper(bw);
|
initBeanWrapper源码:
1
2
3
4
| protected void initBeanWrapper(BeanWrapper bw) {
bw.setConversionService(getConversionService());
registerCustomEditors(bw);
}
|
最终都是会进行转换服务ConversionService和PropertyEditorRegistry的注册,一个是用来进行属性类型转换的,一个是用来属性值解析的。
回调MergedBeanDefinitionPostProcessor
回到doCreateBean中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| BeanWrapper instanceWrapper = null;
if (mbd.isSingleton()) {
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
final Object bean = (instanceWrapper != null ? instanceWrapper.getWrappedInstance() : null);
Class<?> beanType = (instanceWrapper != null ? instanceWrapper.getWrappedClass() : null);
mbd.resolvedTargetType = beanType;
synchronized (mbd.postProcessingLock) {
if (!mbd.postProcessed) {
try {
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
}
catch (Throwable ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Post-processing of merged bean definition failed", ex);
}
mbd.postProcessed = true;
}
}
...
|
这里有一个方法applyMergedBeanDefinitionPostProcessors
1
2
3
4
5
6
7
8
| protected void applyMergedBeanDefinitionPostProcessors(RootBeanDefinition mbd, Class<?> beanType, String beanName) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof MergedBeanDefinitionPostProcessor) {
MergedBeanDefinitionPostProcessor bdp = (MergedBeanDefinitionPostProcessor) bp;
bdp.postProcessMergedBeanDefinition(mbd, beanType, beanName);
}
}
}
|
这里出现了一个接口MergedBeanDefinitionPostProcessor,这个接口也是BeanPostProcessor的子接口。
点击发现这个接口的实现类全是跟注解相关的,包括AutowiredAnnotationBeanPostProcessor、CommonAnnotationBeanPostProcessor及InitDestroyAnnotationBeanPostProcessor 实现类。
回调 postProcessMergedBeanDefinition 方法时,已经拿到了 merged bean definition,并且还未开始 poplateBean 填充 bean 属性、 initlializeBean 初始化 bean 对象, 因此可以在这里对 merged bean definition 进行一些操作 ,在 poplateBean 或 initlializeBean 阶段使用前面操作结果实现所需功能
@PostConstruct,@PreInit、 @Resouce,@Autowired @InitMethod 都在这里实现的
@PostConstruct、@PreDestroy
CommonAnnotationBeanPostProcessor在构造函数中设置了两个注解:@PostConstruct和@PreDestroy,一个是在初始化完之后调用,一个是容器销毁时调用。CommonAnnotationBeanPostProcessor这个类的父类为InitDestroyAnnotationBeanPostProcessor,用于处理初始化和销毁方法的。
CommonAnnotationBeanPostProcessor 的构造器:
1
2
3
4
5
6
| public CommonAnnotationBeanPostProcessor() {
setOrder(Ordered.LOWEST_PRECEDENCE - 3);
setInitAnnotationType(PostConstruct.class);
setDestroyAnnotationType(PreDestroy.class);
ignoreResourceType("javax.xml.ws.WebServiceContext");
}
|
CommonAnnotationBeanPostProcessor 合并方法:
1
2
3
4
5
| public void postProcessMergedBeanDefinition(RootBeanDefinition beanDefinition, Class<?> beanType, String beanName) {
super.postProcessMergedBeanDefinition(beanDefinition, beanType, beanName);
InjectionMetadata metadata = findResourceMetadata(beanName, beanType, null);
metadata.checkConfigMembers(beanDefinition);
}
|
点击postProcessMergedBeanDefinition方法发现调用了父类的这个方法,然后执行了一个叫查找生命周期元数据的方法findLifecycleMetadata。
1
2
3
4
| public void postProcessMergedBeanDefinition(RootBeanDefinition beanDefinition, Class<?> beanType, String beanName) {
LifecycleMetadata metadata = findLifecycleMetadata(beanType);
metadata.checkConfigMembers(beanDefinition);
}
|
查找生命周期元数据findLifecycleMetadata:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| private LifecycleMetadata findLifecycleMetadata(Class<?> clazz) {
if (this.lifecycleMetadataCache == null) {
return buildLifecycleMetadata(clazz);
}
LifecycleMetadata metadata = this.lifecycleMetadataCache.get(clazz);
if (metadata == null) {
synchronized (this.lifecycleMetadataCache) {
metadata = this.lifecycleMetadataCache.get(clazz);
if (metadata == null) {
metadata = buildLifecycleMetadata(clazz);
this.lifecycleMetadataCache.put(clazz, metadata);
}
return metadata;
}
}
return metadata;
}
|
构建生命周期元数据buildLifecycleMetadata:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| private LifecycleMetadata buildLifecycleMetadata(final Class<?> clazz) {
if (!AnnotationUtils.isCandidateClass(clazz, Arrays.asList(this.initAnnotationType, this.destroyAnnotationType))) {
return this.emptyLifecycleMetadata;
}
List<LifecycleElement> initMethods = new ArrayList<>();
List<LifecycleElement> destroyMethods = new ArrayList<>();
Class<?> targetClass = clazz;
do {
final List<LifecycleElement> currInitMethods = new ArrayList<>();
final List<LifecycleElement> currDestroyMethods = new ArrayList<>();
ReflectionUtils.doWithLocalMethods(targetClass, method -> {
if (this.initAnnotationType != null && method.isAnnotationPresent(this.initAnnotationType)) {
LifecycleElement element = new LifecycleElement(method);
currInitMethods.add(element);
...
}
if (this.destroyAnnotationType != null && method.isAnnotationPresent(this.destroyAnnotationType)) {
currDestroyMethods.add(new LifecycleElement(method));
...
}
});
initMethods.addAll(0, currInitMethods);
destroyMethods.addAll(currDestroyMethods);
targetClass = targetClass.getSuperclass();
}
while (targetClass != null && targetClass != Object.class);
return (initMethods.isEmpty() && destroyMethods.isEmpty() ? this.emptyLifecycleMetadata :
new LifecycleMetadata(clazz, initMethods, destroyMethods));
}
|
最终发现实际上就是在解析我们的Bean的方法上是否标记了@PostConstruct注解和@PreDestroy方法,如果有就加入到生命周期元数据中,并且将解析到的方法放入到BeanDefinition的externallyManagedInitMethods和externallyManagedDestroyMethods集合中。
Bean初始化和销毁方法解析和执行流程如下
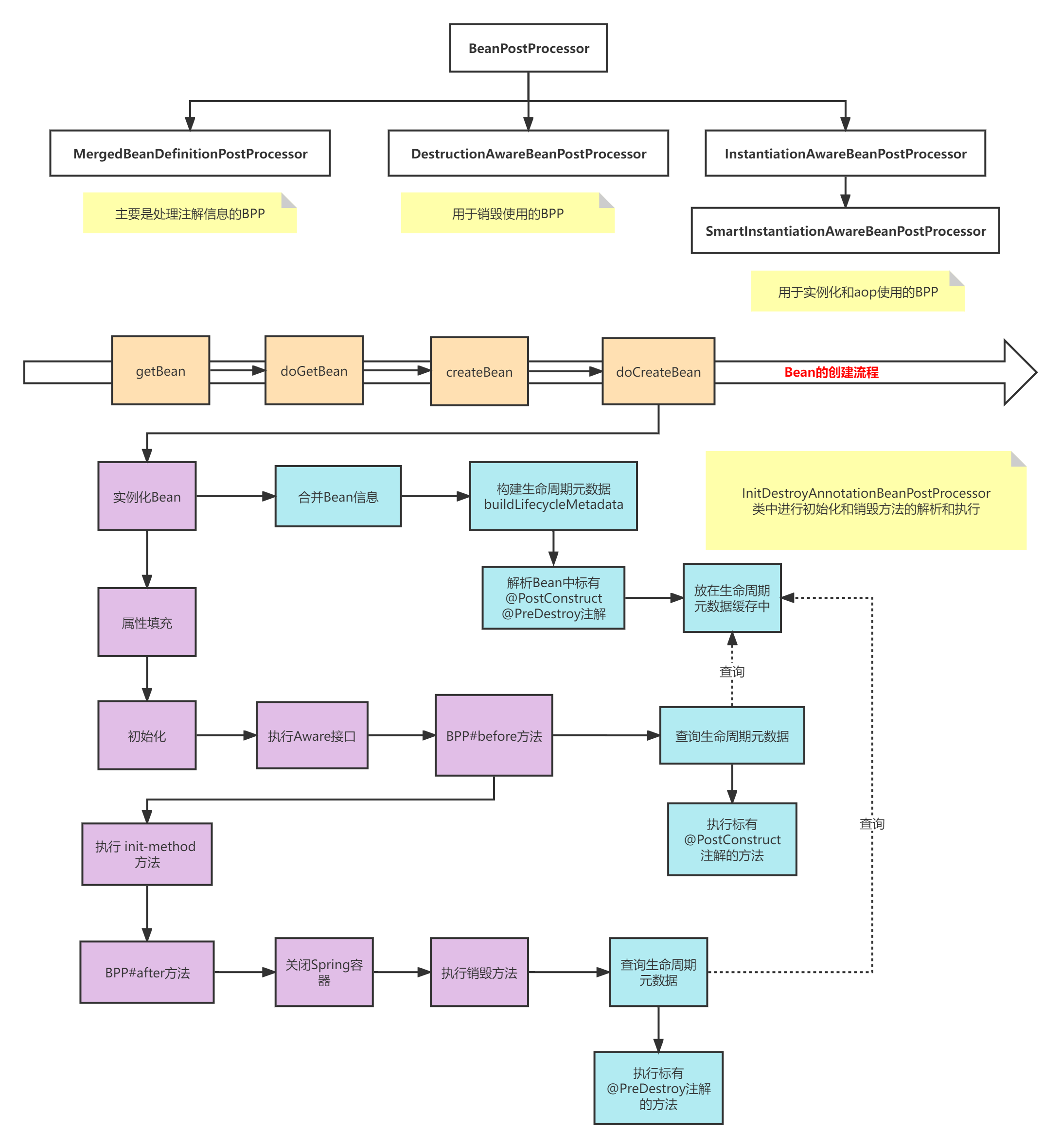
其实InitDestoryAnnotationBeanPostProcessor 主要是对Bean的做了自定义初始化和销毁方法的解析,以及在后期调用BPP时执行。
自动装配注解的解析
在Spring中自动装配的注解一般来说比较常用的有两个,一个@Autowired 是Spring提供的,还有个是@Resource是Java的注解,这两个注解都能够完成自动装配,不过在实现时@Autowired注解是由AutowiredAnnotationBeanPostProcessor解析的和执行,而@Resource注解是由CommonAnnotationBeanPostProcessor解析和执行的。
这些注解的解析跟解析@PostConstruct和@PreDestroy一样,不同的是这几个注解可以标在字段和方法上,解析是需要对字段和方法都要解析,其他实现基本原理一致。
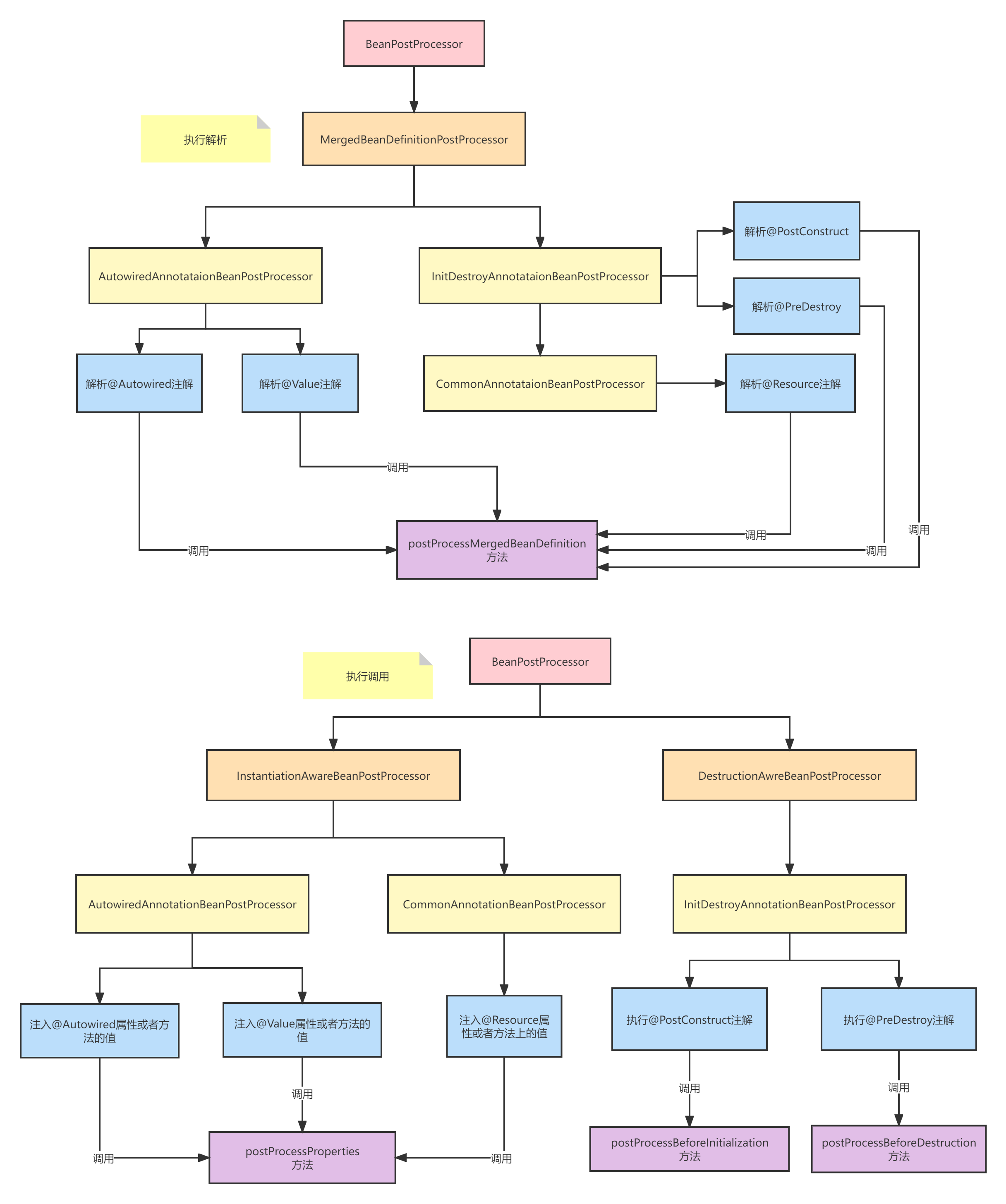
Spring Bean的实例化基本就解析完了,接下来开始解析循环依赖和Bean的属性填充部分。
提前暴露对象
在doCreateBean中,执行完合并之后,会把对象提前暴露出来
1
2
3
4
5
6
7
8
9
10
11
12
13
|
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
|
源码这里就添加了一个lambda表达式到一个Map中,然后结束了,并且明确说明了提前暴露是为了解决循环依赖问题。
什么是循环依赖?
循环依赖顾名思义,就是你中有我,我中有你,打个比方现在有个对象A,他有个属性b,这个属性b是对象B的,然后对象B中有个属性a,属性a是对象A的。
现在开始创建对象,按照Spring的标准创建流程getBean–>doGetBean–>createBean–>doCreateBean,先实例化,然后属性填充,然后执行aware方法,然后执行BeanPostProcessor的before方法,然后执行init-method,然后执行BeanPostProcessor的after方法。那么在执行属性填充时必然会去查找a或者b属性对应的对象,如果找不到就会去创建,那么就会出现下图的样子:
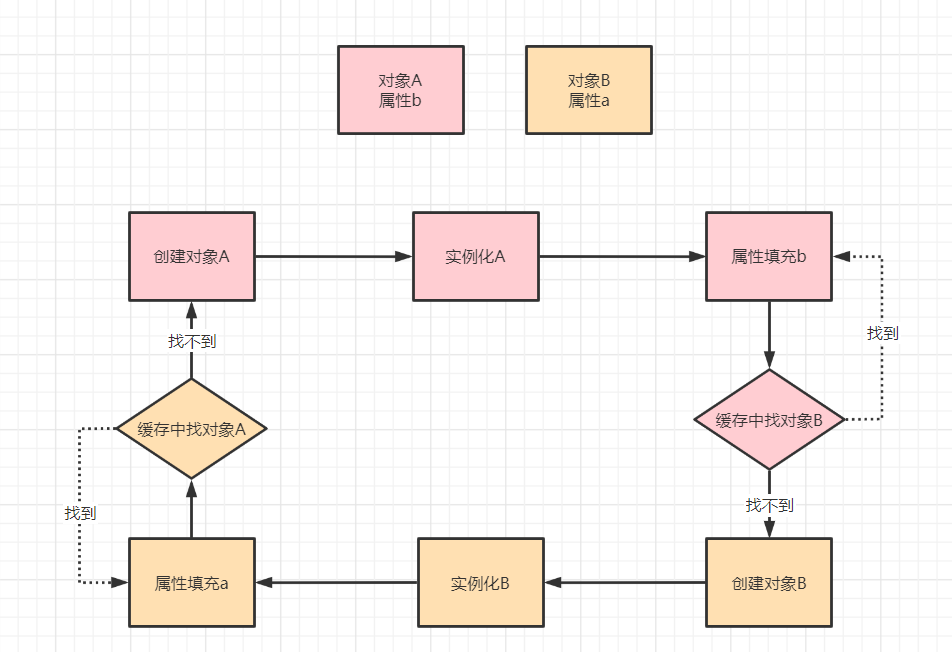
Spring为什么进行提前暴露对象呢
Bean的创建是将实例化和初始化分开的,实例化之后的对象在JVM堆中已经开辟了内存空间地址,这个地址是不会变的,除非山崩地裂,海枯石烂,也就是应用重启了。
因此可以将已经实例化的对象放在另外一个Map中,一般来说都称之为半成品,当填充属性时,可以将先设置半成品对象,等到对象创建完之后在将半成品换成成品,这样的话对象进行属性填充时就可以直接先使用半成品填充,等到开始初始化时再将对象创建出来即可。
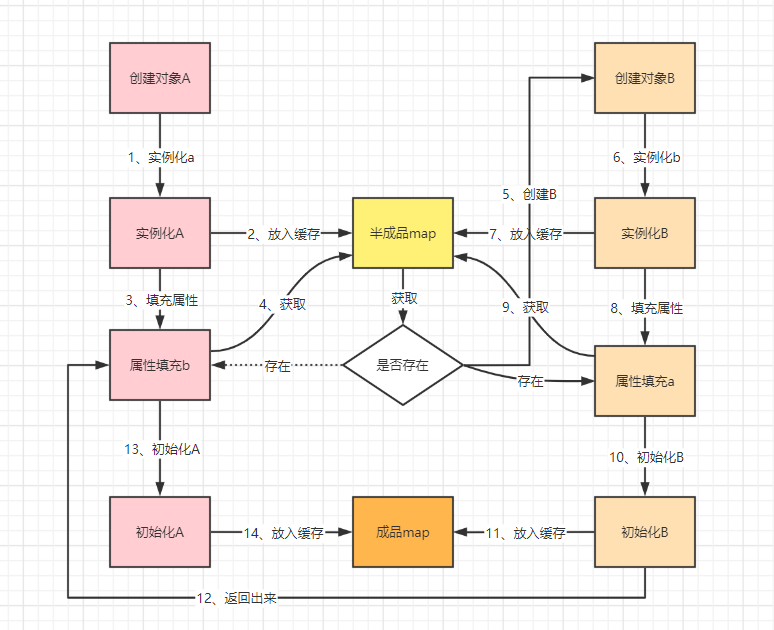
这样看来循环依赖只需要二级缓存就够了,但是在Spring中,存在一种特殊的对象,就是代理对象。也就是说在放入的半成品我们现在多了一种对象,那就是代理对象,这个时候就会出现使用代理对象还是普通对象呢?所以干脆在搞一个Map专门存放代理对象,这样就区分出来了,然后在使用的时候先判断下我们创建的对象是需要代理还是不需要代理,如果需要代理,那么就创建一个代理对象放在map中,否则直接使用普通对象就可以了。
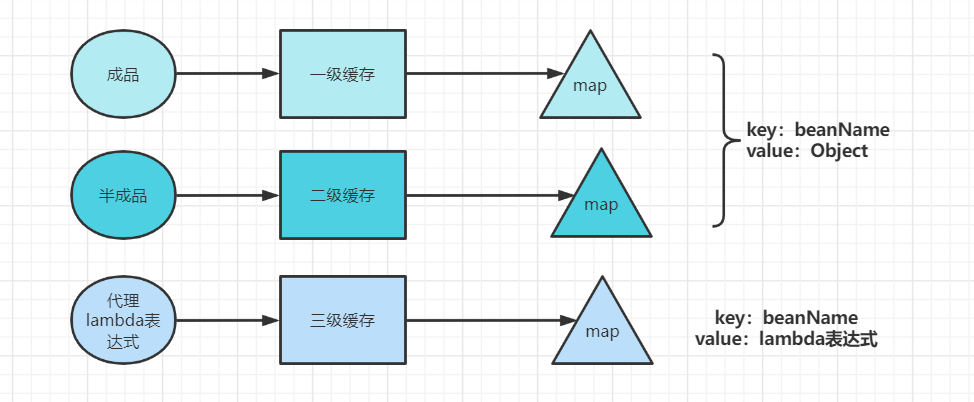
实现方式
Spring是将所有的对象都放在三级缓存中,也就是lambda表达式中。在doCreateBean方法中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
|
在属性填充的时候,会执行到getBean,然后从缓存中获取getSingleton:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| @Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
synchronized (this.singletonObjects) {
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}
|
在获取单例对象时,会执行到三级缓存,然后执行getObject方法,最终就会触发AbstractAutowireCapableBeanFactory#getEarlyBeanReference方法的调用:
1
2
3
4
5
6
7
8
9
10
11
12
13
| protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
|
ibp.getEarlyBeanReference方法在Spring中只有AbstractAutoProxyCreator类进行了实质的实现
1
2
3
4
5
6
7
| public Object getEarlyBeanReference(Object bean, String beanName) {
Object cacheKey = this.getCacheKey(bean.getClass(), beanName);
this.earlyProxyReferences.put(cacheKey, bean);
return this.wrapIfNecessary(bean, beanName, cacheKey);
}
|
wrapIfNecessary
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| protected Object wrapIfNecessary(Object bean, String beanName, Object cacheKey) {
if (StringUtils.hasLength(beanName) && this.targetSourcedBeans.contains(beanName)) {
return bean;
}
if (Boolean.FALSE.equals(this.advisedBeans.get(cacheKey))) {
return bean;
}
if (isInfrastructureClass(bean.getClass()) || shouldSkip(bean.getClass(), beanName)) {
this.advisedBeans.put(cacheKey, Boolean.FALSE);
return bean;
}
Object[] specificInterceptors = getAdvicesAndAdvisorsForBean(bean.getClass(), beanName, null);
if (specificInterceptors != DO_NOT_PROXY) {
this.advisedBeans.put(cacheKey, Boolean.TRUE);
Object proxy = createProxy(
bean.getClass(), beanName, specificInterceptors, new SingletonTargetSource(bean));
this.proxyTypes.put(cacheKey, proxy.getClass());
return proxy;
}
this.advisedBeans.put(cacheKey, Boolean.FALSE);
return bean;
}
|
首先进行了判断,如果不满足创建代理的条件,都是直接返回这个对象,否则进入创建代理的方法,创建出代理对象,最终放入缓存中。点入到最后会发现使用了两种代理创建方式CglibAopProxy和JdkDynamicAopProxy.
参考
https://www.cnblogs.com/redwinter/p/16268667.html
https://www.cnblogs.com/redwinter/p/16286745.html





